⚡ عاجل: كريستيانو رونالدو يُتوّج كأفضل لاعب كرة قدم في العالم●⚡ أخبار عاجلة تتابعونها لحظة بلحظة على خبر●⚡ تابعوا آخر المستجدات والأحداث من حول العالم●
AI اقتراحات ذكية
AI مباشر|--مشاهد مباشر
932,029مقال401مصدر نشط228قناة مباشرة4,889خبر اليوم
آخر تحديث:منذ ثانيتين
How NVIDIA’s Inference Software Stack Powers the Lowest Token Cost
•As organizations move from AI pilots to production AI factories, infrastructure decisions have shifted from peak chip specifications to cost per token: how many useful tokens they can deliver per doll...
•Codesigned with NVIDIA GPUs, CPUs, networking and systems, and strengthened by a broad open source ecosystem, NVIDIA’s full-stack inference software continuously improves hardware performance.
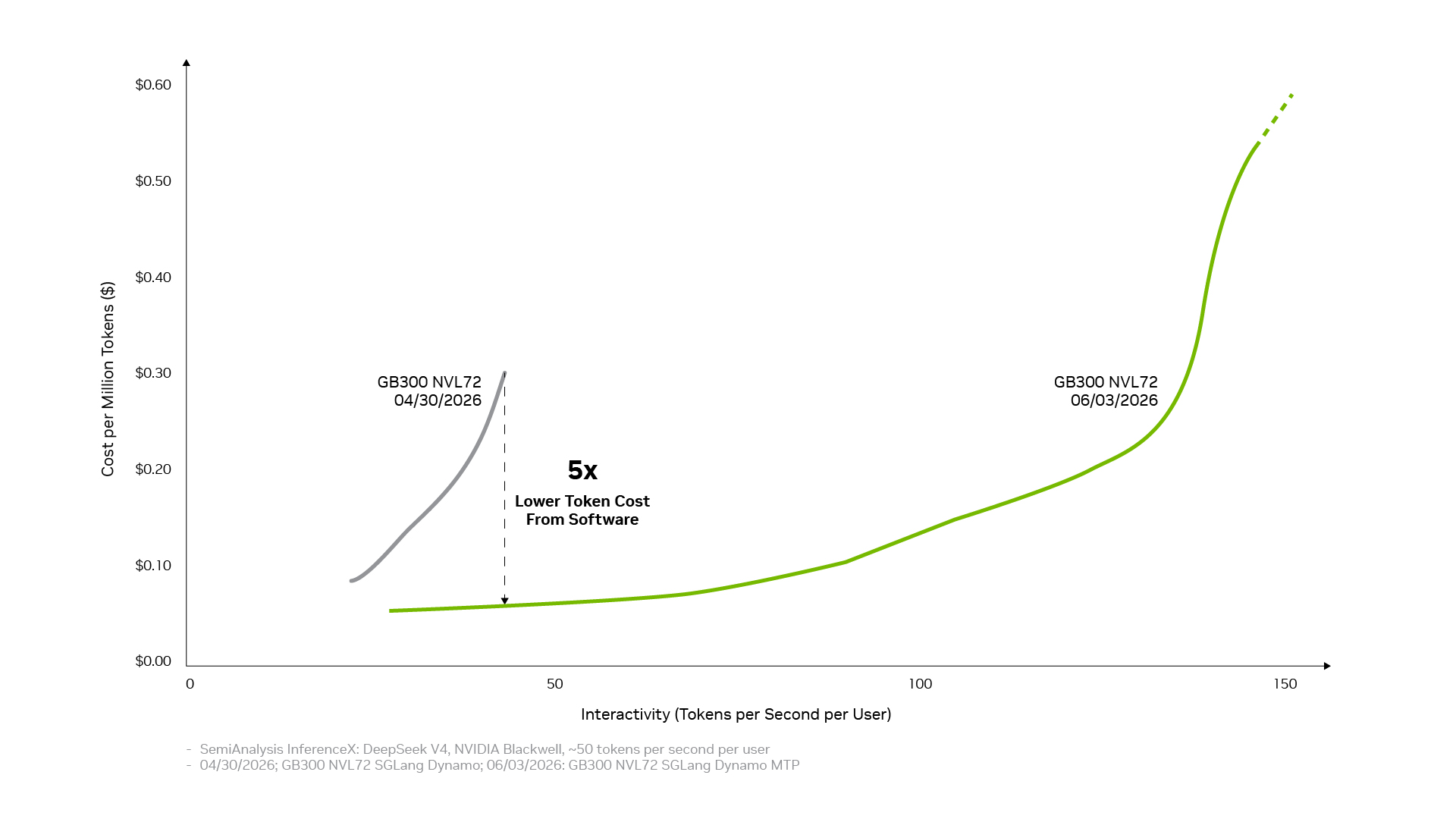
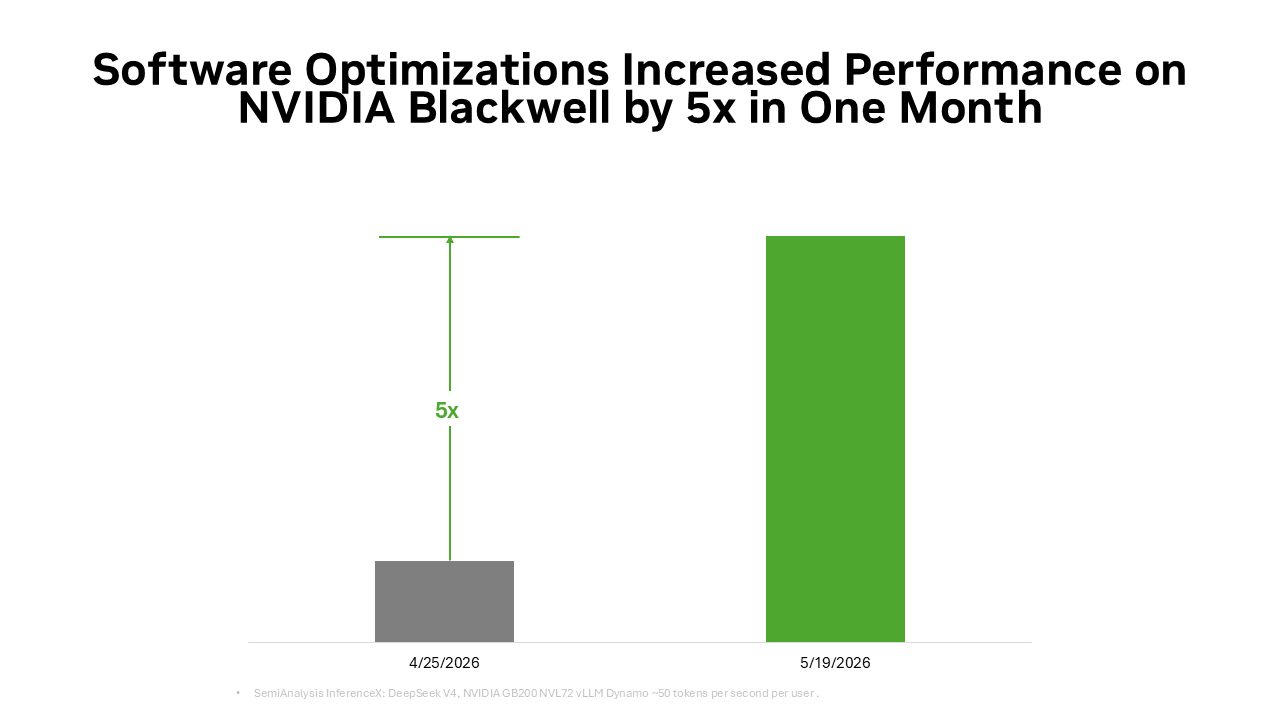
•On the NVIDIA Blackwell platform, the software stack has already reduced token costs by up to 5x on the DeepSeek V4 model in just one month.
هذا الخبر من NVIDIA Blog. خبر يقدم أدوات ذكاء اصطناعي للتلخيص والترجمة والاستماع.
As organizations move from AI pilots to production AI factories, infrastructure decisions have shifted from peak chip specifications to cost per token: how many useful tokens they can deliver per dollar, per watt and within required latency targets.
Codesigned with NVIDIA GPUs, CPUs, networking and systems, and strengthened by a broad open source ecosystem, NVIDIA’s full-stack inference software continuously improves hardware performance. On the NVIDIA Blackwell platform, the software stack has already reduced token costs by up to 5x on the DeepSeek V4 model in just one month.
SemiAnalysis InferenceX results comparing token cost and interactivity for NVIDIA GB300 NVL72 systems with SGLang and the NVIDIA Dynamo inference framework.
Leading companies and inference providers are already seeing the compounding value of NVIDIA’s inference software stack on Blackwell:
Baseten used the NVIDIA TensorRT-LLM open source library to serve DeepSeek V4 Pro on Blackwell GPUs for reasoning, coding and long-context workloads, applying proprietary runtime optimizations to deliver up to 50% more tokens per second.
Cognition is using the NVIDIA Dynamo inference framework to manage inference GPUs, giving its team a ready-made path to scale reinforcement learning workloads without needing to build that infrastructure from scratch.
Deep Infra uses the NVIDIA inference software stack to serve frontier open source models performantly on Blackwell from day zero, including DeepSeek V4.
Together AI used NVIDIA TensorRT-LLM on Blackwell to help Cursor accelerate the path from model optimizations to production endpoints for its real-time coding experience.
Why Software Matters for Inference Economics
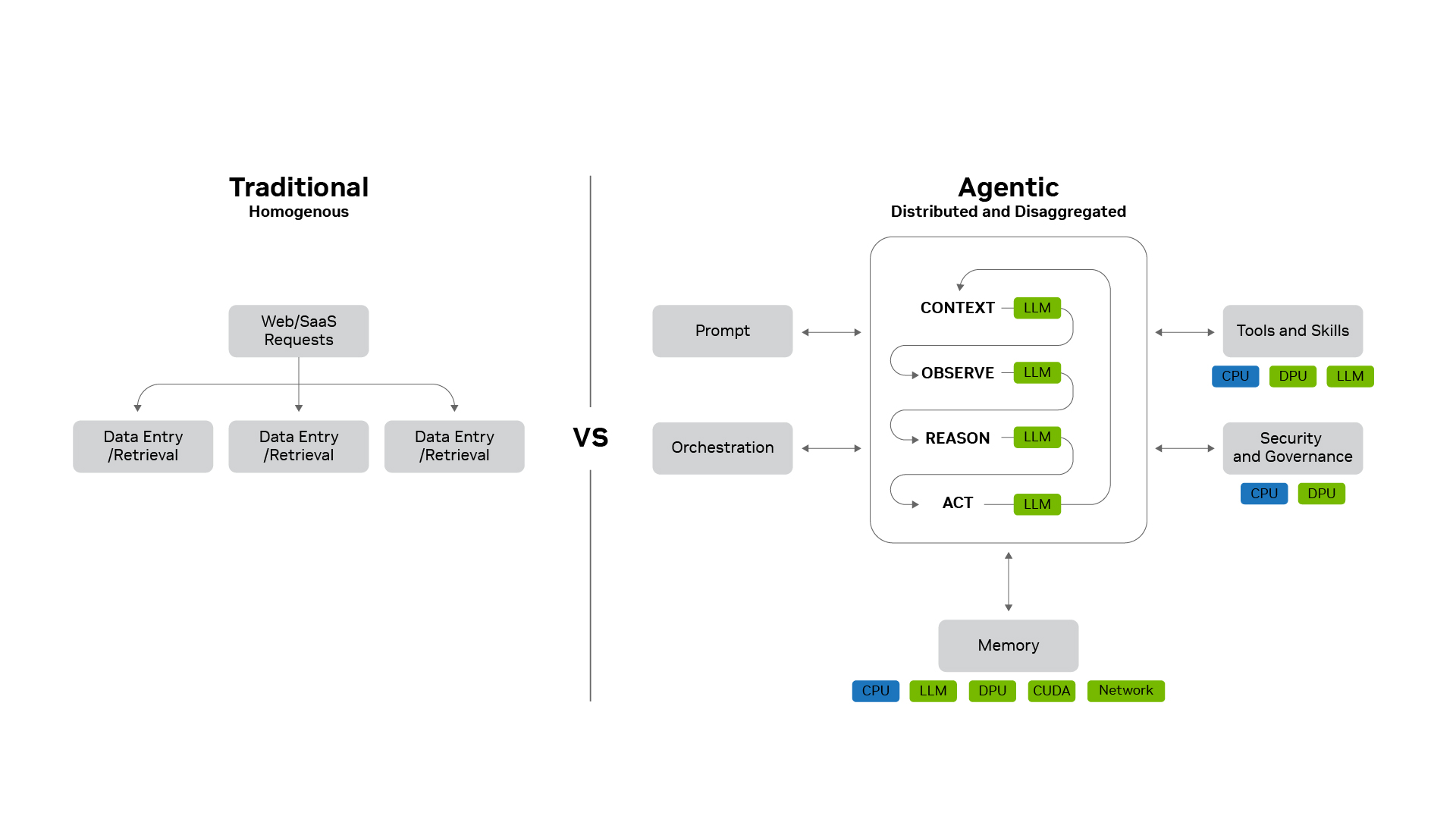
Traditional web, search and software-as-a-service workloads were relatively predictable: A user might load a page, refresh a feed or update a business record. These requests typically followed similar software paths, reading from or writing to a database, and scaled by adding more of the same servers.
Agentic AI is different.
Agentic AI runs distributed, stateful workflows that span LLMs, tools, memory, security, networking and accelerated computing across the data center.
Agents can reason, plan, call tools, spin up specialist subagents and manage massive context across multi-turn workflows. They turn a single request into a distributed computing problem that can span hundreds of subagents, thousands of tasks and multiple large language models, running across GPUs, CPUs, DPUs and storage systems.
The software stack determines whether that complexity turns into wasted capacity or lower cost per token.
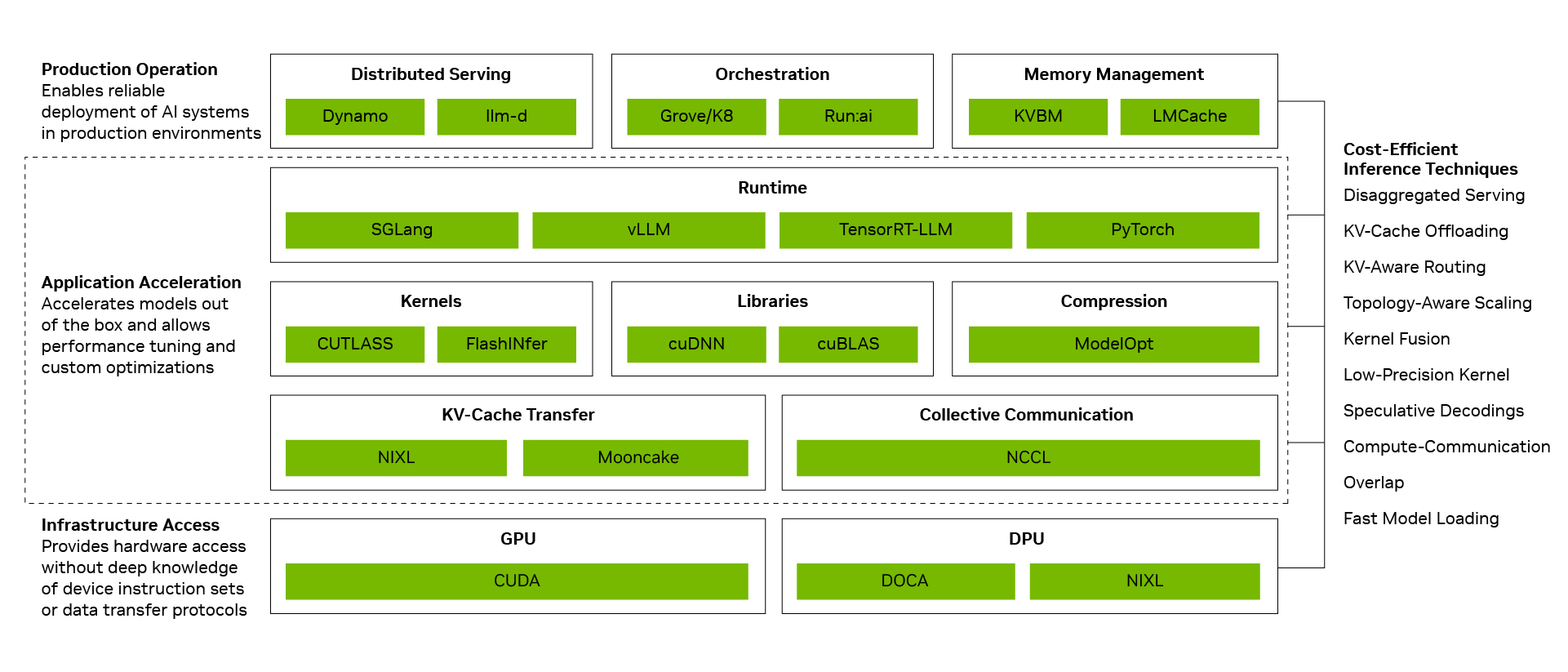
Lower cost per token comes from turning individual optimizations into system-level performance. NVIDIA’s inference software stack does this by connecting three layers:
Production Operation: Coordinates distributed serving, orchestration, autoscaling and memory management so inference can run across the right compute and storage resources.
Application Acceleration: Runs models with high performance while giving developers room to tune and customize, using runtime optimizations such as overlapping compute and communication and kernel fusion.
Infrastructure Access: Exposes NVIDIA GPU, networking, memory and system capabilities without requiring developers to manage every device instruction set or data-transfer protocol directly.
The NVIDIA software stack spans model serving, runtime scheduling, kernels, communication libraries and hardware-aware optimizations, enabling rapid performance gains and lower serving costs as improvements compound across layers.
When these layers work as one system, individual optimizations compound.
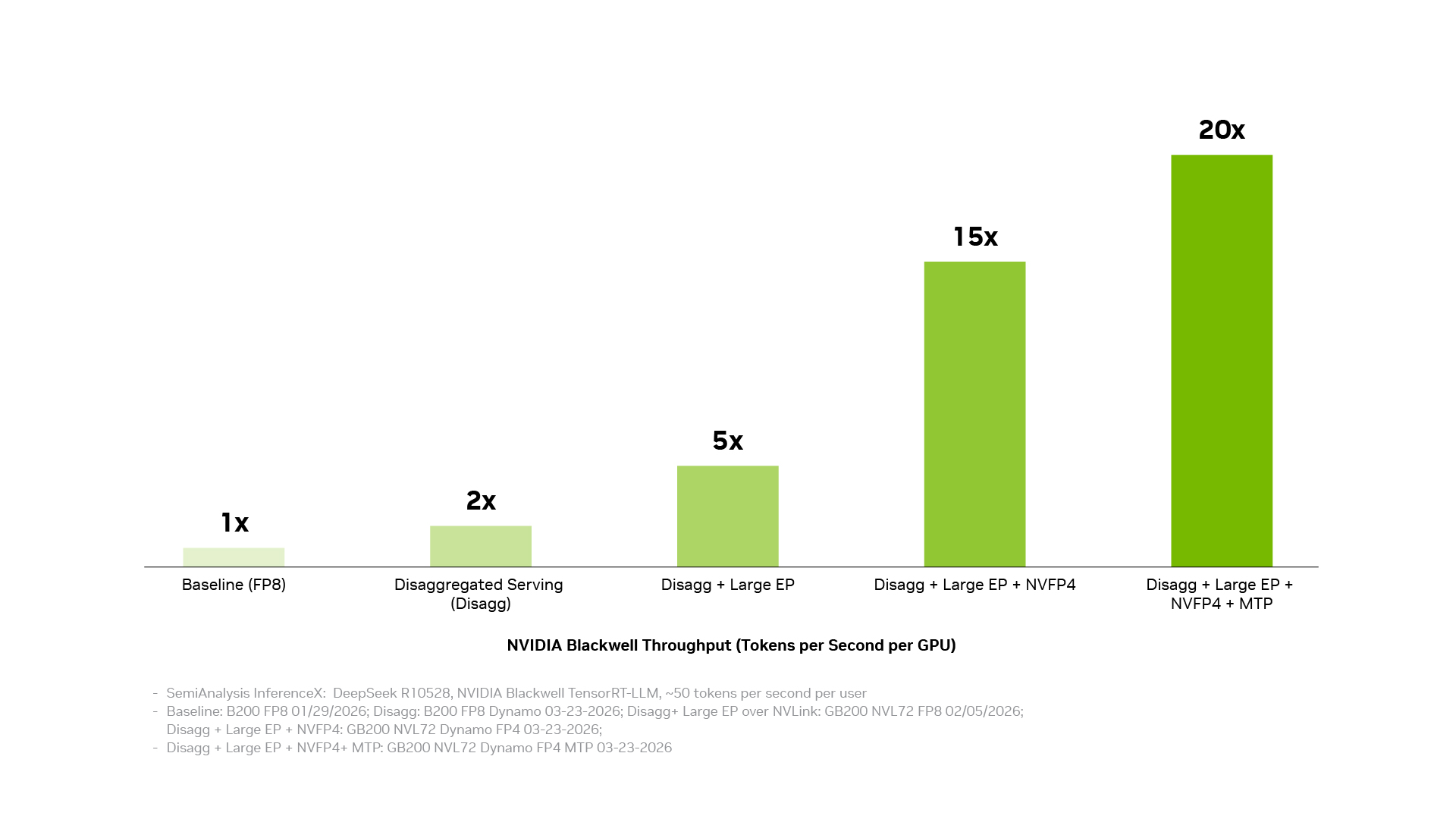
Disaggregated serving, large expert parallelism over NVIDIA NVLink interconnect technology, NVFP4 precision and multi-token prediction each deliver meaningful gains on their own. Combined, they increase throughput by up to 20x.
The chart below shows the result. Capturing that gain in production is complex, requiring coordination across the full inference stack — from production operations and model runtimes to kernels, communication libraries and hardware access. NVIDIA’s inference software stack is designed to make those layers work together so each optimization can build on the others.
Stacking software optimizations compounds performance gains, increasing NVIDIA Blackwell token throughput per GPU from baseline to up to 20x with disaggregated serving, large expert parallelism (Large EP), NVFP4 and multi-token prediction (MTP).
Open Source Amplifies the Full-Stack Advantage
That same full-stack foundation is amplified by the open source ecosystem. Many of today’s most widely used open source AI frameworks and inference projects are built natively on NVIDIA CUDA, which means new research and software optimizations run with leading performance on NVIDIA GPUs from day zero.
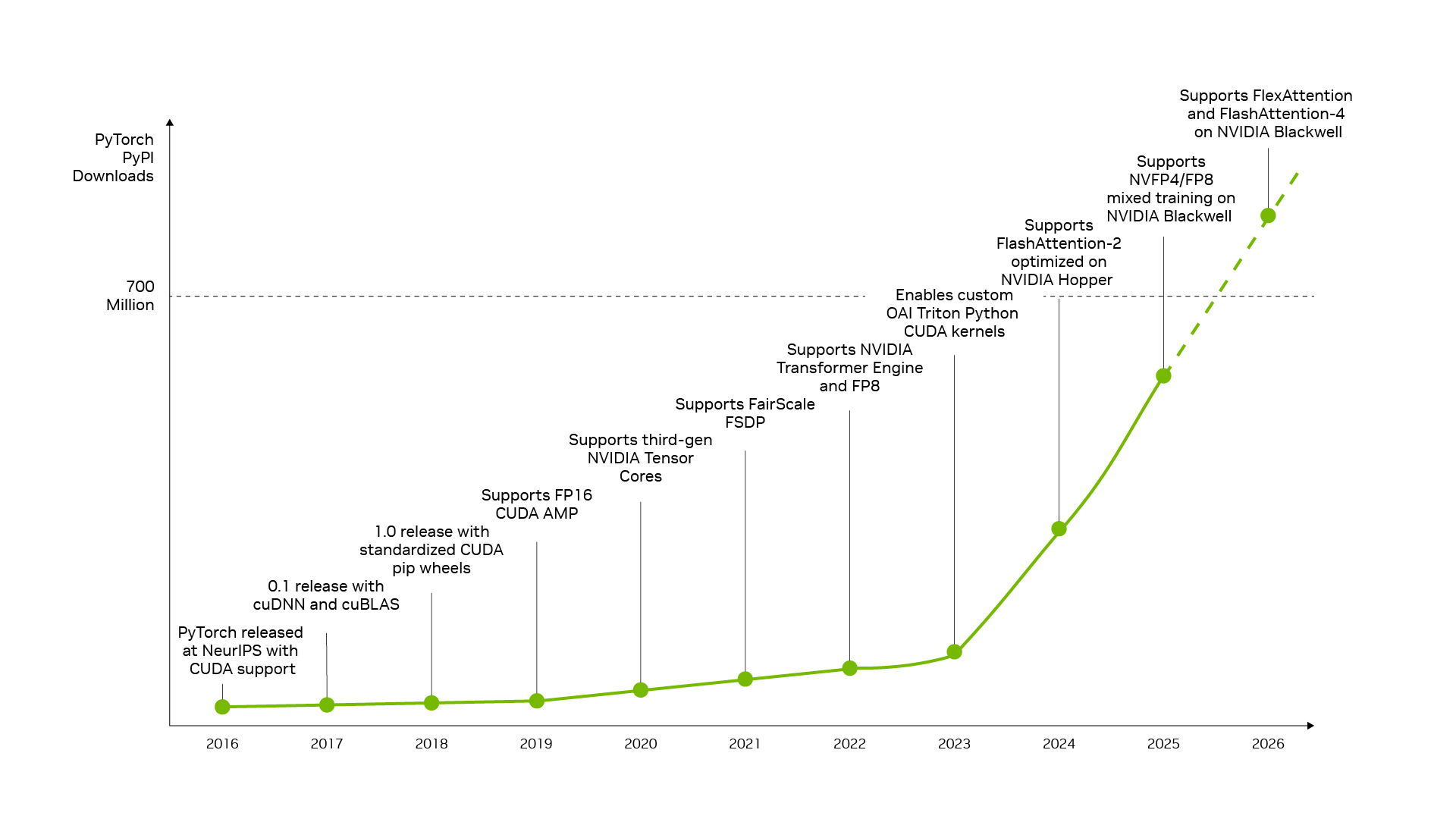
PyTorch is a leading example. Launched in 2016 with native CUDA support, PyTorch has coevolved with NVIDIA’s architecture, giving developers access to innovations such as Tensor Cores, Transformer Engine and NVFP4 directly through a familiar framework.
When breakthroughs such as DFlash speculative decode, which delivers up to 15x more throughput on existing hardware, or FastVideo, which generates 1080p videos in less than five seconds, land in PyTorch, they can run instantly on NVIDIA, helping AI factories convert research progress into lower token costs.
NVIDIA and PyTorch codevelopment helps bring new AI software innovations to developers, helping turn CUDA-native advances into production performance as PyTorch adoption grows.
The same open source momentum is why when a new frontier open model like DeepSeek V4 is released, leading inference frameworks like vLLM and SGLang have day-zero deployment recipes for the NVIDIA Blackwell architecture — making the model accessible across millions of Blackwell GPUs. It’s also why DeepSeek V4 performance on Blackwell improved by up to 5x within about a month across vLLM and SGLangframeworks, cutting token costs to roughly one-fifth of previous levels.
SemiAnalysis InferenceX results comparing token throughput at same interactivity for NVIDIA GB200 NVL72 systems with vLLM and the NVIDIA Dynamo inference framework.
That’s the open source flywheel: more developers optimize CUDA-native inference paths, more production deployments feed back into the ecosystem and each software improvement increases delivered token output while lowering cost per token over time.
ملاحظة تحريرية | Editorial Note:
نُشر هذا المقال في الأصل بواسطة NVIDIA Blog.
خبر (Khabr) هي منصة إعلامية أردنية مرخّصة تعمل بالذكاء الاصطناعي.
نضيف قيمة تحريرية من خلال: تحليل ذكي للأخبار، ملخصات تلقائية، رواية صوتية بالذكاء الاصطناعي، ترجمة متعددة اللغات، وتدقيق الحقائق.
هدفنا جعل الأخبار أكثر وضوحاً وسهولةً للقارئ العربي.
This article was originally published by NVIDIA Blog.
Khabr is a licensed Jordanian AI-powered news platform (Registration #82086).
We add editorial value through: AI-powered news analysis, automated summaries, AI audio narration, multi-language translation (Arabic, English, French, Turkish), and AI fact-checking.
Our mission is to make news more accessible and understandable for Arabic-speaking audiences worldwide.
هذا الخبر ضمن تغطية خبر لقسم تكنولوجيا.
نقدّم لك تحليلات ذكية وملخصات يومية لأهم الأخبار من مصادر موثوقة متعددة.
المصدر: NVIDIA Blog.
يوجد 6 مقالات مرتبطة بهذا الموضوع.
This article is part of Khabr's coverage of Technology.
We provide AI-powered analysis, summaries, and multi-source aggregation to keep you informed.
Source: NVIDIA Blog.
🍪 نستخدم ملفات تعريف الارتباط لتحسين تجربتك وعرض الإعلانات المخصصة. باستخدامك للموقع، فإنك توافق على سياسة ملفات تعريف الارتباط وسياسة الخصوصية.
We use cookies to enhance your experience and show personalized ads. By using this site, you agree to our Cookie Policy and Privacy Policy.
🔍
FREEFree 1GB Internet + Free International Calls
$1 trial — eSIM in 190+ countries — No roaming charges